|
|
|
|
Data Science News
|
[1507.04779v1] From Cosmic Birth to Living Earths: The Future of UVOIR Space Astronomy
|
arXiv, Astrophysics > Instrumentation and Methods for Astrophysics
from July 16, 2015
For the first time in history, humans have reached the point where it is possible to construct a revolutionary space-based observatory that has the capability to find dozens of Earth-like worlds, and possibly some with signs of life. This same telescope, designed as a long-lived facility, would also produce transformational scientific advances in every area of astronomy and astrophysics from black hole physics to galaxy formation, from star and planet formation to the origins of the Solar System. The Association of Universities for Research in Astronomy (AURA) commissioned a study on a next-generation UVOIR space observatory with the highest possible scientific impact in the era following JWST. This community-based study focuses on the future space-based options for UV and optical astronomy that significantly advance our understanding of the origin and evolution of the cosmos and the life within it. The committee concludes that a space telescope equipped with a 12-meter class primary mirror can find and characterize dozens of Earth-like planets and make fundamental advances across nearly all fields of astrophysics. The concept is called the High Definition Space Telescope (HDST). The telescope would be located at the Sun-Earth L2 point and would cover a spectral range that, at a minimum, runs from 0.1 to 2 microns. Unlike JWST, HDST will not need to operate at cryogenic temperatures. HDST can be made to be serviceable on orbit but does not require servicing to complete its primary scientific objectives. We present the scientific and technical requirements for HDST and show that it could allow us to determine whether or not life is common outside the Solar System. We do not propose a specific design for such a telescope, but show that designing, building and funding such a facility is feasible beginning in the next decade – if the necessary strategic investments in technology begin now.
|
| |
Under the Hood of Amazon EC2 Container Service – All Things Distributed
|
Werner Vogels, All Things Distributed blog
from July 20, 2015
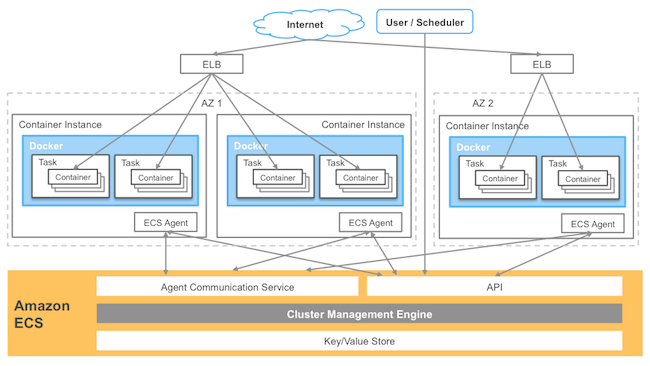
In my last post about Amazon EC2 Container Service (Amazon ECS), I discussed the two key components of running modern distributed applications on a cluster: reliable state management and flexible scheduling. Amazon ECS makes building and running containerized applications simple, but how that happens is what makes Amazon ECS interesting. Today, I want to explore the Amazon ECS architecture and what this architecture enables. Below is a diagram of the basic components of Amazon ECS:
|
| |
KDD Cup 2015 winners announced
|
Revolution Analytics, Revolutions blog
from July 20, 2015
The KDD Cup is an annual competition to build the best predictive model from a large data set. This years’ contest tasked entrants to predict the likelihood of a student dropping out from one of XuetangX’s massively-online open courses, based on the student’s prior activities. The competition closed on July 12, and yesterday, the winning teams were announced. The winner was team “Intercontinental Ensemble” and the runner-up was “FEG&NSSOL@DataVeraci”.
|
| |
Which movies get artificial intelligence right? | Science/AAAS | News
|
Science/AAAS, News
from July 17, 2015
In the opening scene of the 1982 film Blade Runner, an interrogator asks an android named Leon questions “designed to provoke an emotional response.” According to the movie, empathy is one of the few features that distinguish humans from artificial intelligence (AI). When the test shifts to questions about his mother, Leon stands up, draws a gun, and shoots his interviewer to death.
It’s not a happy ending for the human, but when Hollywood portrays AI, it rarely is. Writers and directors have been pitting man against machine on the silver screen for decades, but just how scientifically plausible are these plots? We consulted a group of AI experts and asked them to weigh in on 10 different films in the genre. We’ve ranked them least to most plausible.
|
| |
Presenting Watson News Explorer – Watson Dev
|
IBM, Watson Dev blog
from July 20, 2015
Huge volumes of news are published every minute. No single human being could hope to keep up with the hundreds of thousand of news stories being generated daily.
With Watson we can now observe and understand the richness of information that is emerging as it’s obtained right from the source. From the freely available text of news reports, we are using natural language processing to extract Topics and essential entities such as Locations, Organizations, Companies, People, and Time. These are the key components required in order to build and navigate the gigantic network of interconnected, heterogeneous information that is implicit in the news.
For example, imagine you are interested in a specific announcement made by IBM about Watson Explorer at an event in Rio de Janeiro yesterday. Which articles talk about this announcement? Is this news related to other IBM products, or other events, or companies? What news articles were written about these related entities? The News Explorer tool can be used to investigate these questions and more.
|
| |
Google News Lab Mashes Big Data With Old-School Reporting
|
Fast Company
from July 17, 2015
On July 8, Philadelphia police stopped 22-year-old Tyree Carroll on his bicycle and repeatedly beat him after he was already on the ground. More than a dozen officers eventually surrounded Carroll as he called for his grandmother, who lived nearby, for help. We know this because activist Jasmyne Cannick recorded the encounter on a phone and uploaded it to her YouTube channel.
Google is no longer just a place to search for news stories; it’s a place to find raw news itself. Among the 432,000 hours of video uploaded to YouTube every day are user clips of important events—from police beatings to political uprisings—that no media crew was around to cover. Google’s trend analysis based on 3.5 billion daily searches can surface patterns in data that traditional reporting misses.
But there’s a lot of noise in the signal, and what rises to the top isn’t always the cream. “Algorithms alone aren’t enough to make YouTube and sites like it valuable. You need curation, you need journalism,” says Steve Grove, a Google executive and former reporter who realized a year ago that the search giant could do more to serve journalists. His idea grew into Google News Lab, a suite of tools for the media that the company formally announced last month.
|
| |
How to choose a machine learning API to build predictive apps — Medium
|
Medium, Louis Dorad
from July 20, 2015
Two years ago, Mike Gualtieri of Forrester Research coined the term “predictive applications” and pitched it as the “next big thing in app development”. Today, some people estimate that more than 50% of the apps on a typical smartphone have predictive features. Predictive apps were defined by Gualtieri as “apps that provide the right functionality and content at the right time, for the right person, by continuously learning about them and predicting what they’ll need.” For that, they use Machine Learning (ML) techniques and data.
ML APIs such as the ones provided by Amazon Machine Learning, BigML, Google Prediction API and PredicSis all promise to make it easy for developers to apply ML to data and thus to add predictive features to their apps. While previous libraries and tools were designed for scientists and PhDs, these APIs provide a much needed abstraction layer for developers to integrate ML in real-world apps.
|
| |
Ibis on Impala: Python at Scale for Data Science
|
Cloudera Engineering Blog
from July 20, 2015
This new Cloudera Labs project promises to deliver the great Python user experience and ecosystem at Hadoop scale.
Across the user community, you will find general agreement that the Apache Hadoop stack has progressed dramatically in just the past few years. For example, Search and Impala have moved Hadoop beyond batch processing, while developers are seeing significant productivity gains and additional use cases by transitioning from MapReduce to Apache Spark.
Thanks to such advances in the ecosystem, Hadoop has evolved into a robust and powerful open source data analysis stack. A centerpiece of that stack is Impala, the MPP query engine that is still the only open source option for a truly interactive, BI-style experience (an analytic database, if you will) on Hadoop. For business analysts in particular, who are the rank-and-file of big data consumers, the Hadoop experience is becoming all but indistinguishable from that of traditional data infrastructure but with unprecedented scale, flexibility, and cost-effectiveness under the covers.
|
| |
Events
|
Space Apps Next Gen
Space Apps Next Gen is the first two-day high school hackathon where teams of diverse populations of students from the Greater New York City Area will learn, collaborate, and engage with publicly available data to solve real world scientific challenges. The event will bring together and expose 100 students to the powerful fusion of data and programming with science, tapping their potential to solve the problems of tomorrow.
Saturday-Sunday, August 29-30, in New York City, exact location TBD
|
| |
Deadlines
|
WORKSHOP ON INFORMATION IN NETWORKS (WIN)
|
deadline: subsection?
|
WIN is a Social Networks Summit intended to foster collaboration and to build community. The increasing availability of massive networked data is revolutionizing the scientific study of a variety of phenomena in fields as diverse as Computer Science, Economics, Physics and Sociology. Yet, while many important advances have taken place in these different communities, the dialog between researchers across disciplines is only beginning. The purpose of WIN is to bring together leading researchers studying ‘information in networks’ – its distribution, its diffusion, its value, and its influence on social and economic outcomes – in order to lay the foundation for ongoing relationships and to build a lasting multidisciplinary research community.
Friday-Saturday, October 2-3, at Stern School of Business, NYU
Abstract Submission Deadline: Friday, August 21
|
| |
|