|
|
|
|
Data Science News
|
Mike Jordan and BDAS in Science
|
UC Berkeley, AMPLab
from July 31, 2015
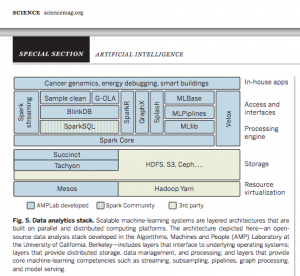
The BDAS Stack made its debut in the prestigious journal Science earlier this month. A Review article by our own Mike Jordan and CMU’s Tom Mitchell entitled “Machine Learning: Trends, Perspectives and Prospects” appeared in the July 17, 2015 issue (subscription required), and includes the following diagram (which should be familiar to the AMPLab:faithful):
|
| |
Ibis Design: Modeling high level analytics tasks — Ibis Project Blog
|
Wes McKinney, Ibis Project
from August 10, 2015
Outside of scalability and high performance on large data sets with Python, Ibis is focused on simplifying analytics tasks for end users. By designing a rich pandas-like domain specific language (DSL) embedded in Python code, we can hide away the complexities normally associated with expressing analytical concepts in SQL or some other tool. This post gives some specific examples and shows how we’re solving them in Ibis.
|
| |
Looking Back on the Class of 2015 Fellowship
|
hackNY
from August 10, 2015
It’s been a week since hackNY Fellowship ended with a spectacular Demo Night, and we’re already missing our Class of 2015 Fellows. Our 34 Fellows had an action-packed 10 weeks of interning at local startups and attending our Speaker Series talks, workshops, mixers with the alumNY, and activities around the city. Applications for the Class of 2016 will open on September 26th, at the hackNY Fall Hackathon!
Our Startups this year were exciting and diverse, ranging from small, early-stage startups like Betterpath and Ufora to household names like Buzzfeed, Kickstarter, and Foursquare. Every startup came with a project or series of projects for their Fellow to work on – each Fellow shipped real code this summer! – and a mentor to guide them and answer their questions. Our students worked on projects from data visualization to ad fraud detection to tools for their dev teams.
|
| |
JournalMap
|
USDA Agricultural Research Service, Jornada Experimental Range
from August 10, 2015
JournalMap is a scientific literature search engine that empowers you to find relevant research based on location and biophysical attributes combined with traditional keyword searches.
|
| |
Mapping NYC Taxi Data
|
Daniel Forsyth
from August 07, 2015
Earlier this week the New York City Taxi & Limousine Commission officially released yellow and green taxi trip record data for all of 2014 and up to June of 2015. This includes millions of records that include pick-up and drop-off dates and times, pick-up and drop-off locations, trip distances, itemized fares, rate types, payment types, and driver-reported passenger counts. The data, which was previously only available through submission of a formal Freedom of Information Law (FOIL) request, is available in CSV format as well as from Google’s BigQuery tools [1].
After seeing the aforementioned comment and its accompanying visualization I wanted to have a go at replicating it in python. The first step was getting the data into pandas. In this situation it was much easier to query the data from GBQ than to download the individual CSV files. (Note that you must have the google-api-python-client installed and and be logged into GBQ and create a new project for this to work properly). Pandas has an included pandas.io.gbq module that allows you to parse the results of a GBQ query into a dataframe very easily. The following query creates a dataframe that includes the latitude and longitude of all pickup locations in 2015, this ends up being around 750,000 records.
|
| |
Multilevel Models and Political Advertising
|
Bad Hessian, Adam Slez
from August 11, 2015
The graph above recently appeared as part of Scott Walker’s Twitter feed. Presumably, the idea is to suggest that under Walker’s leadership, Wisconsin has done better than the country as a whole when it comes to unemployment, though an alternative version of the ad makes it somewhat more personal, using the same basic figures to suggest that Walker—a Republican presidential candidate—is outperforming sitting Democratic president Barack Obama. In these ads, the Walker campaign repeatedly highlights the fact that the unemployment rate in Wisconsin is lower than the national average. Note, however, that the unemployment rate in Wisconsin was already lower than the national average when Walker took office. In other words, Walker inherited a good labor market. If we want to measure Walker’s effect on the Wisconsin economy, we need to look at changes in the unemployment rate over time.
I decided to throw some data at the problem. To put Wisconsin’s performance in perspective, I estimated the effect of time on the monthly seasonally-adjusted unemployment rate in each state. Covering the period from January 1, 2011 to June 1, 2015, the data came from the Bureau of Labor Statistics—the same source used by Walker and company.
|
| |
How We Use Data to Suggest Tags for Your Story — Data Lab — Medium
|
Medium, Data Lab
from August 11, 2015
Here on Medium, we envision tags to be central in organizing and connecting ideas. Follow the tags you’re interested in and Medium will help deliver the right content to you. To do that we’d like as many writers as possible to tag their posts. For writers, we’d love to help you find your audience.
So how can we use data to improve how tags are used?
Our solution: suggest tags.
|
| |
Building the Next New York Times Recommendation Engine
|
The New York Times, Open blog
from August 11, 2015
The New York Times publishes over 300 articles, blog posts and interactive stories a day.
Refining the path our readers take through this content — personalizing the placement of articles on our apps and website — can help readers find information relevant to them, such as the right news at the right times, personalized supplements to major events and stories in their preferred multimedia format.
In this post, I’ll discuss our recent work revamping The New York Times’s article recommendation algorithm, which currently serves behind the Recommended for You section of NYTimes.com.
|
| |
Complexity science pioneer John Holland passes away at 86
|
Santa Fe Institute
from August 10, 2015
John Holland, a pioneer in the study of complex adaptive systems and the leading figure in what became known as genetic algorithms, passed away Sunday morning in Ann Arbor, Michigan.
|
| |
AMA Data Scientist: Dr. El-ad David Amir (Custora) : datascience
|
reddit.com/r/datascience
from August 12, 2015
Dr. El-ad David Amir (LinkedIn profile) has been a Data Scientist at Custora for the past 2+ years. His academic background includes a BS in CS, a masters in CS, and a PhD in Biology.
|
| |
|