|
|
Data Science News
|
Tweet of the Week
|
Twitter, J.K. Rowling
from August 16, 2016

|
| |
Make Data Sharing Routine to Prepare for Public Health Emergencies
|
PLOS Medicine, Essay; Jean-Paul Chretien et al.
from August 16, 2016
The acute health threat of outbreaks provides a strong argument for more complete, quick, and broad sharing of research data during emergencies. But the Ebola and Zika outbreaks suggest that data sharing cannot be limited to emergencies without compromising emergency preparedness. To prepare for future outbreaks, the scientific community should expand data sharing for all health research.
|
| |
The Exome Aggregation Consortium (ExAC) database: shedding light on human genetic variation
|
YouTube, Broad Institute
from August 17, 2016
Based on the largest resource of its kind, members of the Exome Aggregation Consortium (ExAC) led by scientists at the Broad Institute of MIT and Harvard report scientific findings from data on the exome sequences (protein-coding portions of the genome) from 60,706 people from diverse ethnic backgrounds. Containing over 10 million DNA variants – many very rare and most identified for the first time – the ExAC dataset is a freely available, high-resolution catalog of human genetic variation that has already made a major impact on clinical research and diagnosis of rare genetic diseases.
|
| |
Analysis of protein-coding genetic variation in 60,706 humans
|
Nature
from August 17, 2016
Large-scale reference data sets of human genetic variation are critical for the medical and functional interpretation of DNA sequence changes. Here we describe the aggregation and analysis of high-quality exome (protein-coding region) DNA sequence data for 60,706 individuals of diverse ancestries generated as part of the Exome Aggregation Consortium (ExAC). This catalogue of human genetic diversity contains an average of one variant every eight bases of the exome, and provides direct evidence for the presence of widespread mutational recurrence. We have used this catalogue to calculate objective metrics of pathogenicity for sequence variants, and to identify genes subject to strong selection against various classes of mutation; identifying 3,230 genes with near-complete depletion of predicted protein-truncating variants, with 72% of these genes having no currently established human disease phenotype. Finally, we demonstrate that these data can be used for the efficient filtering of candidate disease-causing variants, and for the discovery of human ‘knockout’ variants in protein-coding genes.
|
| |
Machine Intelligence 2.0 in charts and graphs
|
VentureBeat, Spoke Software
from August 16, 2016

Almost half of these machine intelligence companies didn’t exist a few years ago, which suggests that the space will be inundated with new companies in the next few years.
|
| |
Commonwealth Awards $5 Million to UMass Amherst to Support New Data Science Collaborative
|
UMass Amherst
from August 17, 2016
“The Baker-Polito administration announced a $5 million grant to the University of Massachusetts Amherst to establish the UMass Amherst Data Science/Cybersecurity Research and Education Collaborative, a public-private partnership designed to accelerate data science innovation in the Pioneer Valley region of Western Massachusetts.”
Not such good news in Ohio:
University of Akron puts the brakes on data science center (August 17, cleveland.com)
|
| |
Data Science Challenges
|
KDnuggets, Neil Lawrence
from August 17, 2016
“This post is thoughts for a talk given at the UN Global Pulse lab in Kampala as part of the second Data Science in Africa Workshop at the UN Global Pulse Lab in Kampala, Uganda. It covers challenges in data science.”
“Data is a pervasive phenomenon. It affects all aspects of our activities. This diffusiveness is both a challenge and an opportunity. A challenge, because our expertise is spread thinly: like raisins in a fruitcake, or nuggets in a gold mine. It is an opportunity, because if we can resolve the challenges of difussion we can foster a multi-faceted benefits across the entire University.”
|
| |
Calico makes another big hire in quest to unlock healthy aging
|
San Francisco Business Times
from August 17, 2016
Daphne Koller, who cofounded online education site Coursera Inc., will be chief computing officer at Alphabet Inc.-backed aging research company Calico Life Sciences LLC.
The three-year-old company, led by former Genentech Inc. CEO Art Levinson, said Wednesday that Koller will build a team zeroing in on computational and machine learning tools for analyzing biological and medical data sets.
|
| |
Engagement 101: Providence and Brown University showcase a data-driven partnership
|
Sunlight Foundation Blog, Azeezat Adeleke
from August 15, 2016
Last spring, Providence’s Department of Innovation partnered with the students and teachers of Public Policy 1802, an undergraduate course at Brown University. This partnership serves as a fantastic model for how local policymakers can work with the academic community in their cities to improve public policy.
It also demonstrates how open data policy can serve as a tool to make these partnerships even more productive. Using city data and public information on city hearings, courtesy of the open meetings portal, students conducted research that City Hall could later turn into solutions.
|
| |
ACL 2016
|
Claudia Hauff
from August 12, 2016
In this post, I have collected the 15 most interesting papers I came across when attending the 2016 Association for Computational Linguistics conference – my first time at ACL.
|
| |
How Smart Data Is Beating Big Data in the Fintech Industry
|
Tech.co
from August 15, 2016
The new wave in information theory and management for the fintech industry is called smart data. … I recently spoke with Patrick Koeck, chief operating officer at Creamfinance, Europe’s top fintech company and a leading firm in smart data, who shared his insights into the usefulness of the new information procuring procss.
|
| |
Genetic Misdiagnoses and the Potential for Health Disparities
|
New England Journal of Medicine; Arjun K. Manrai et al.
from August 18, 2016
For more than a decade, risk stratification for hypertrophic cardiomyopathy has been enhanced by targeted genetic testing. Using sequencing results, clinicians routinely assess the risk of hypertrophic cardiomyopathy in a patient’s relatives and diagnose the condition in patients who have ambiguous clinical presentations. However, the benefits of genetic testing come with the risk that variants may be misclassified. [full text]
|
| |
Social Consumer Market Insights
|
BrandWatch, Natalie Meehan
from August 16, 2016
We hosted a roundtable; an open and frank discussion to understand how brands are using social data to glean valuable consumer insights.
The roundtable event included leaders from some of the world’s biggest brands and agencies, and involved an in-depth exploration around the subject of social consumer marketing insights.
|
| |
Why Marketers Must Focus On Data ‘Far Beyond Location’ to Build a Sharper Picture Of Consumers
|
Street Fight magazine
from August 15, 2016
Tom Laband, the CEO of adsquare, recently spoke with Street Fight about the rise of mobile data, the positive impact on targeting and the company’s wider strategy to “go far beyond location” to provide intelligent mobile data for holistic and effective mobile campaigns.
|
| |
Events
|
International Data Week, September 11-17
Denver, CO “The International Data Week will bring together data scientists, researchers, industry leaders, entrepreneurs, policy makers and data stewards to explore how best to exploit the data revolution to improve our knowledge and benefit society through data-driven research and innovation.” [$$$]
|
| |
Deadlines
|
NASA’s Space Robotics Challenge: The Tasks, the Prizes, and How to Participate
|
deadline: Contest/Award
|
“Before the SRC itself, there’s a qualification round. A simulated R5 will have to identify a pattern of colored lights blinking on a panel, push a button, and walk through a doorway without falling down. The 20 top scoring teams (based on speed and accuracy) will each get US $15,000 and move on to the virtual competition.”
Deadline to register will remain open until September 16.
|
| |
Computational Health
|
deadline: Conference
|
Perth, Australia “We invite research contributions for the 26th World Wide Web Conference Computational Health Track.”
Deadline for abstract submission is Wednesday, October 19.
|
| |
Tools & Resources
|
Making Kaggle the Home of Open Data
|
Kaggle, no free hunch blog; Ben Hamner
from August 17, 2016
Kaggle is best known for running machine learning competitions. These competitions have helped classify whales in the oceans and galaxies in the sky; they’ve helped diagnose diabetic retinopathy and predict ad clicks.
Today, we’re expanding beyond machine learning competitions and opening Kaggle Datasets up to everyone. You can now instantly share and publish data through Kaggle.
|
| |
Academic Technical Debt
|
Zachary M. Jones
from August 14, 2016
Technical debt is “a concept in programming that reflects the extra development work that arises when code that is easy to implement in the short run is used instead of applying the best overall solution.”
Although most often spoken of as a problem in software engineering for industry, academia has a severe technical debt problem. The problem is that even in the rare case that you can obtain the code and data used to generate the analysis contained in a paper, often the code is broken (I am presuming that it was at some past point not broken).
This in turn requires debugging of a foreign codebase which may or may not (probably the latter) have been written in a manner intended to be understandable to people other than the original author. Often this means that the code isn’t ever fixed.
|
| |
R for Data Science – Wrangling section
|
R for Data Science book, Hadley Wickham
from August 17, 2016
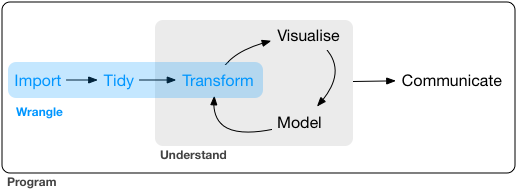
“In this part of the book, you’ll learn about data wrangling, the art of getting your data into R in a useful form for visualisation and modelling.”
|
| |
Careers
|
| Career Advice |
How can preprints help my career?
Software Carpentry, LeafSpring
|
| |
| Tenured and tenure track faculty positions |
Assistant / Associate Professor of Research Ethics, Kansas Univ. Medical Center
University of Kansas; Kansas City, MO
|
| |
Assistant or Associate Professor, Dept. of Linguistics
New York University; New York, NY
|
| |
Assistant Professor; Department of Communication
Cornell University; Ithaca, NY
|
| |
| Postdocs |
Genomics Postdocs-Computational Biology Department – Carnegie Mellon University
Carnegie Mellon University
|
| |
Postdoc position available immediately
t+z statistics, Columbia University
|
| |