|
|
Data Science News
|
Newly launched Genomic Data Commons to facilitate data and clinical information sharing
|
National Institutes of Health
from June 06, 2016
The Genomic Data Commons (GDC), a unified data system that promotes sharing of genomic and clinical data between researchers, launched today with a visit from Vice President Joe Biden to the operations center at the University of Chicago. An initiative of the National Cancer Institute (NCI), the GDC will be a core component of the National Cancer Moonshot and the President’s Precision Medicine Initiative (PMI), and benefits from $70 million allocated to NCI to lead efforts in cancer genomics as part of PMI for Oncology. The GDC will centralize, standardize and make accessible data from large-scale NCI programs such as The Cancer Genome Atlas (TCGA) and its pediatric equivalent, Therapeutically Applicable Research to Generate Effective Treatments (TARGET).
|
| |
New Method Seeks to Diminish Risk, Maximize Investment in Cancer “Megafunds”
|
NYU News
from June 06, 2016
Recognizing the high research and development costs for drugs to combat cancer, a team of researchers has devised a method to maximize investment into these undertakings by spotting which efforts are the most scientifically viable. … This was the aim of the method, reported in the journal Oncotarget and developed by New York University’s Bud Mishra.
Also, in cancer research:
Newly launched Genomic Data Commons to facilitate data and clinical information sharing (June 06, National Institutes of Health)
How web search data might help diagnose serious illness earlier (June 07, The Official Microsoft Blog, Next at Microsoft)
|
| |
75 | Listening to Data From Space with Scott Hughes
|
Data Stories; Enrico Bertini, Moritz Stefaner and guest, Scott Hughes
from June 01, 2016
Dear friends, we are really excited to publish our first “data sonification” episode ever! After many years of searching for the right person, subject and format, we are happy to publish this fantastic episode with Scott Hughes from MIT. Scott is an astrophysicist and a key figure at LIGO, the laser interferometer project that finally allowed scientists to “listen” to the sound of two colliding black holes.
Here Scott talks about how he decided to sonify his data and how sonification is being used by scientists to understand astrophysical phenomena. [audio, 57:38]
|
| |
Stanford’s ‘Jackrabbot’ robot will attempt to learn the arcane and unspoken rules of pedestrians
|
TechCrunch, Devin Coldewey
from June 02, 2016
It’s hard enough for a grown human to figure out how to navigate a crowd sometimes — so what chance does a clumsy and naive robot have? To prevent future collisions and awkward “do I go left or right” situations, Stanford researchers are hoping their “Jackrabbot” robot can learn the rules of the road.
The team, part of the Computational Vision and Geometry Lab, has already been working on computer vision algorithms that track and aim to predict pedestrian movements. But the rules are so complex, and subject to so many variations depending on the crowd, the width of the walkway, the time of day, whether there are bikes or strollers involved — well, like any machine learning task, it takes a lot of data to produce a useful result.
|
| |
Using AI to build a comprehensive database of knowledge
|
O'Reilly Radar, Data Show Podcast, Ben Lorica
from June 02, 2016
Extracting structured information from semi-structured or unstructured data sources (“dark data”) is an important problem. One can take it a step further by attempting to automatically build a knowledge graph from the same data sources. Knowledge databases and graphs are built using (semi-supervised) machine learning, and then subsequently used to power intelligent systems that form the basis of AI applications. The more advanced messaging and chat bots you’ve encountered rely on these knowledge stores to interact with users.
In this episode of the Data Show, I spoke with Mike Tung, founder and CEO of Diffbot – a company dedicated to building large-scale knowledge databases. [audio, 39:34]
|
| |
Where are the Opportunities for Machine Learning Startups?
|
KDnuggets, Libby Kinsey
from June 07, 2016
Machine Learning and AI are fast becoming ubiquitous in data driven businesses, that is to say, an awful lot of businesses. Here I choose a few areas where it’s possible that big corporations haven’t already eaten everybody’s lunch. It’s not uncharted territory?—?if I could think of the next killer application, I’d be trying to do it!
|
| |
MET network in PubMed: a text-mined network visualization and curation system
|
The Journal of Biological Databases and Curation
from May 30, 2016
Metastasis is the dissemination of a cancer/tumor from one organ to another, and it is the most dangerous stage during cancer progression, causing more than 90% of cancer deaths. Improving the understanding of the complicated cellular mechanisms underlying metastasis requires investigations of the signaling pathways. To this end, we developed a METastasis (MET) network visualization and curation tool to assist metastasis researchers retrieve network information of interest while browsing through the large volume of studies in PubMed. MET can recognize relations among genes, cancers, tissues and organs of metastasis mentioned in the literature through text-mining techniques, and then produce a visualization of all mined relations in a metastasis network. To facilitate the curation process, MET is developed as a browser extension that allows curators to review and edit concepts and relations related to metastasis directly in PubMed. PubMed users can also view the metastatic networks integrated from the large collection of research papers directly through MET. For the BioCreative 2015 interactive track (IAT), a curation task was proposed to curate metastatic networks among PubMed abstracts. Six curators participated in the proposed task and a post-IAT task, curating 963 unique metastatic relations from 174 PubMed abstracts using MET. [full text]
|
| |
Opinion: Big data biomedicine offers big higher education opportunities
|
Proceedings of the National Academy of Sciences; John Darrell Van Horn
from June 07, 2016
I like to tell my students a story about a time back in the “olden days” of the early 1990s when I was a newly minted postdoctoral fellow at the National Institutes of Health. Our laboratory conducted brain imaging studies using positron emission tomographic imaging and would routinely obtain 6–12 functional image volumes per subject in our experiments. The director of our neuroimaging laboratory asked me to explore the purchase of a new computer hard drive capable of storing our growing collection of brain imaging data files. At that time, we had already accumulated quite a number of subjects and wanted to easily access their data for a variety of different statistical analyses—and we expected to obtain much more data.
So I searched, and I compared and contrasted, rating drive quality, price, and capacity. With our not-so-expansive $4,000 budget, I eventually decided on the drive that would surely satisfy our needs. It was among the largest self-contained external hard drives of its kind at that time. Its massive 4 gigabyte capacity seemed infinite. People would come to visit the laboratory to just gaze upon it.
|
| |
A New Air Pollution Database Is Good, but Imperfect
|
Scientific American Blog Network; Angel Hsu, David Wong, Carlin Rosengarten
from June 07, 2016
The World Health Organization (WHO) recently released its latest global urban air pollution database, including information for nearly 3,000 cities—a doubling from the 2014 database, which itself had data from 500 more cities than the previous (2011) iteration. These increases in coverage in air pollution measurement and reporting is encouraging, but the WHO numbers reveal that we still have a ways to go to construct a comprehensive and accurate picture of global air quality.
|
| |
R Passes SAS in Scholarly Use (finally)
|
r4stats.com
from June 08, 2016

Way back in 2012 I published a forecast that showed that the use of R for scholarly publications would likely pass the use of SAS in 2015.
|
| |
How web search data might help diagnose serious illness earlier
|
The Official Microsoft Blog, Next at Microsoft
from June 07, 2016
Early diagnosis is key to gaining the upper hand against a wide range of diseases. Now Microsoft researchers are suggesting that records of the topics that people search for on the Internet could one day prove as useful as an X-ray or MRI in detecting some illnesses before it’s too late.
The potential of using engagement with search engines to predict an eventual diagnosis – and possibly buy critical time for a medical response — is demonstrated in a new study by Microsoft researchers Eric Horvitz and Ryen White, along with former Microsoft intern and Columbia University doctoral candidate John Paparrizos.
In a paper published Tuesday in the Journal of Oncology Practice, the trio detailed how they used anonymized Bing search logs to identify people whose queries provided strong evidence that they had recently been diagnosed with pancreatic cancer.
|
| |
Tweet of the Week
|
Twitter, Leonard Speiser
from June 09, 2016

|
| |
Bias against Novelty in Science: A Cautionary Tale
|
National Bureau of Economic Research
from June 01, 2016
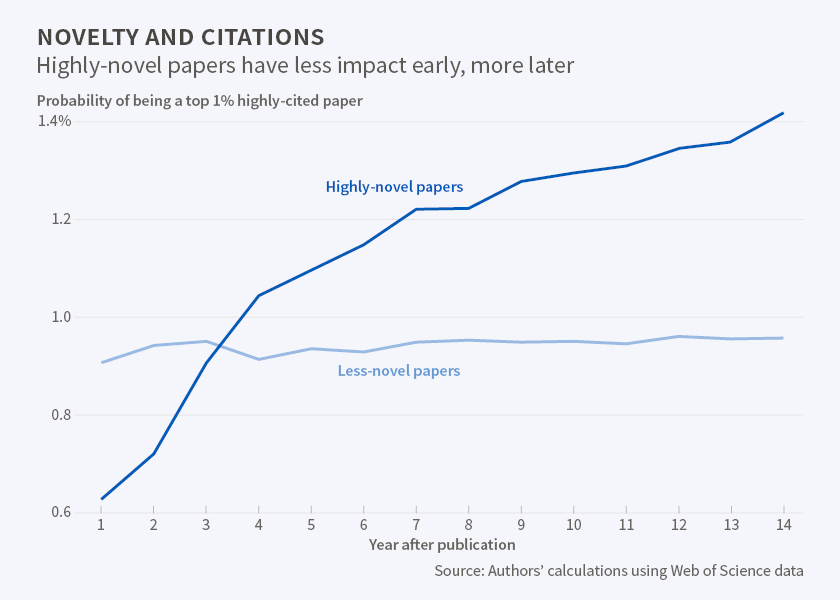
Research based on an unusual or novel approach may lead to important breakthroughs in science, but peer evaluators are often overly cautious in evaluating such work, Jian Wang, Reinhilde Veugelers, and Paula Stephan find in Bias against Novelty in Science: A Cautionary Tale for Users of Bibliometric Indicators (NBER Working Paper No. 22180).
|
| |
Psychologists grow increasingly dependent on online research subjects
|
Science, Latest News
from June 07, 2016
Last month’s studies on MTurk—which include a test of the limits of people’s generosity, a comparison of religiosity and humility, and a measurement of the psychological impact of graphic warnings on cigarette packages—took only days from start to finish.
But the platform’s popularity has raised concerns, as researchers discussed at the Association for Psychological Science meeting in Chicago, Illinois, last month. Some worry that they are becoming too dependent on a commercial platform. “Academic research would be really screwed if Amazon decided to shut it down,” says Todd Gureckis, a psychologist at New York University (NYU) in New York City. Others question whether the research volunteers are paid fairly and treated ethically. And looming over it all are questions about who these anonymous volunteers actually are, and concerns that they are less numerous and diverse than researchers hope.
|
| |
Tweet of the Week
|
Twitter
from June 09, 2016

|
| |
Tweet of the Week
|
Twitter
from June 09, 2016

|
| |
Events
|
Data Cuisine | Exploring food as a form of data expression
The Data Cuisine Workshop is an experimental investigation on the representation of data with culinary means, or — if you like — edible diagrams.
Boston, MA Thursday-Friday, June 23-24 at Northeastern University [$$]
|
| |
Tools & Resources
|
ParaText: CSV parsing at 2.5 GB per second
|
Wise.io
from June 07, 2016
Despite extensive use of distributed databases and filesystems in data-driven workflows, there remains a persistent need to rapidly read text files on single machines. Surprisingly, most modern text file readers fail to take advantage of multi-core architectures, leaving much of the I/O bandwidth unused on high performance storage systems. Introduced here, ParaText, reads text files in parallel on a single multi-core machine to consume more of that bandwidth. The alpha release includes a parallel Comma Separated Values (CSV) reader with Python bindings. … In our tests, ParaText can load a CSV file from a cold disk at a rate of 2.5 GB/second and 4.2 GB/second out-of-core from a warm disk. ParaText can parse and perform out-of-core computations on a 5 TB CSV file in under 30 minutes.
|
| |
OpenAI Requests for Research
|
OpenAI
from June 08, 2016
It’s easy to get started in deep learning, with many resources to learn the latest techniques. But it’s harder to know what problems are worth working on.
We’re publishing a living collection of important and fun problems to help new people enter the field, and for enthusiastic practitioners to hone their skills. Many will require inventing new ideas.
|
| |
Release TensorFlow v0.9.0 RC0 · tensorflow/tensorflow · GitHub
|
GitHub – tensorflow
from June 06, 2016
Major Features and Improvements
Python 3.5 support and binaries
Added iOS support
Added support for processing on GPUs on MacOS
And more
|
| |
All-in-one Docker image for Deep Learning
|
GitHub – saiprashanths
from June 07, 2016
Here are Dockerfiles to get you up and running with a fully functional deep learning machine. It contains all the popular deep learning frameworks with CPU and GPU support (CUDA and cuDNN included). The CPU version should work on Linux, Windows and OS X. The GPU version will, however, only work on Linux machines.
|
| |
Careers
|
|
Postdoctoral Research Associate – Politics
Princeton University
|
| |
Image assay development postdoc job description
Broad Institute of Harvard and MIT
|
| |