Android is known for its poor security issues, especially with the older versions of the OS. Although, the latest build of Android are vastly secure than what Google was putting out on smartphones years ago, it still has not managed to found the largest bug on the software. As a result, the company has increased the reward value of its “bug bounty” program to as much as $200,000, hoping to attract more software engineers and researchers.
The trio of investigations are part of NASA’s Convergent Aeronautics Solutions (CAS) project and are expected to take between 24 and to 30 months to complete.
“Our idea is to invest a very modest amount of time and money into new technologies that are ambitious and potentially transformative,” said Richard Barhydt, NASA’s acting director of the Transformative Aeronautics Concepts Program (TACP). “They may or may not work, but we won’t know unless we try.”
Urs Hölzle has a big job. As senior vice president of technical infrastructure at Google, he’s in charge of the hundreds of thousands of servers in data centers spread across the planet to power the company’s ever widening range of services.
He’s also the person that the company’s engineers turn to when all that computing power turns out not to be enough.
Today at the 2017 Wired Business Conference in New York, Hölze explained that even with its enormous resources, Google has had to find ways to economize its operations in order to meet its ambitious goals. Most recently, he said, the company was forced to start building its own artificial intelligence chips because the company’s existing infrastructure just wouldn’t cut it.
General Electric (GE) was co-founded in 1897 by Thomas Edison. Today, 120 years later, GE is the single company with the longest continual presence in the Dow Jones Industrial Average, and is undergoing one of the most dramatic transformation initiatives of any major company. Mainstream legacy businesses should take note. In a matter of only a few years, GE has migrated from being an industrial and consumer products and financial services firm to a “digital industrial” company with a strong focus on the “Industrial Internet” and $7 billion in software sales in 2016.
This is the story of how GE has accomplished this digital transformation by leveraging AI and machine learning fueled by the power of Big Data.
One day I’d love to see a careful, thoughtful intellectual history of the origins of AI in general and of the computational turn in language in particular, but we don’t have one, so I’m free to make up my own comedic version.
What I am against is a tendency of the “deep-learning community” to enter into fields (NLP included) in which they have only a very superficial understanding, and make broad and unsubstantiated claims without taking the time to learn a bit about the problem domain. This is not about “not yet establishing a common language”. It is about not taking time and effort to familiarize yourself with the domain in which you are working. Not necessarily with all the previous work, but with basic definitions. With basic evaluation metrics. Claiming “state of the art results on Chinese Poetry Generation” (from the paper’s abstract) is absurd. Saying “we evaluate using a CFG” without even looking at what the CFG represents is beyond sloppy. Using the likelihood assigned by a PCFG as a measure that “captures the grammaticality of a sentence” is just plain wrong (in the sense of being incorrect, not of being immoral).
In his keynote at the Microsoft Build conference earlier this year, the head of Microsoft’s AI and Research Harry Shum hinted that at some point the Microsoft Azure cloud service will give developers access to field programmable gate arrays (FPGAs). Azure Chief Technology Officer Mark Russinovich also talked about Azure exposing “[FPGAs] as a service for you sometime in the future.”
What is that FPGA-powered future going to look like and how are developers going to use it?
At Los Alamos National Laboratory, home to more than 100 supercomputers since the dawn of the computing era, elegance and simplicity of programming are highly valued but not always achieved. In the case of a new product, dubbed “Charliecloud,” a crisp 800-line code helps supercomputer users operate in the high-performance world of Big Data without burdening computer center staff with the peculiarities of their particular software needs.
2. What do you think the paper of the future will look like?
It’s already here, if you know where to look. “A decision underlies phototaxis in an insect”, by E. Axel Gorostiza et al., is a beautiful example of how to “package” an experimental paper together with all its materials. Even better, senior author Björn Brembs wrote a blog post about it that explains the meaning and context of the paper to non-experts like me. Of course, this is the paper of the near future, since Brembs and others are already using these approaches; we just need to figure out how to drive adoption. As for the far future, who knows?
In any event, I’m not convinced we know how papers “should” be written or communicated; it’s easier to talk about important goals. First, primary research papers must contain the details (data, source code, models, statistics) necessary to replicate any results. They should contain context for the study, and at least some guarded interpretation of the results. And they should be archivable, so that we can revisit the paper in 5, 15, or 50 years and be able to read and understand it in some detail.
I’ve been vocal on Twitter about a deep-learning for language generation paper titled “Adversarial Generation of Natural Language” from the MILA group at the university of Montreal (I didn’t like it), and was asked to explain why.
Cortana might be getting a makeover. Two separate reports today from Thurrott and Windows Central mention the possibility of a changed UI for Cortana that’ll make it more conversational. Generally, both stories allude to the idea that Microsoft is trying to make it easier to both discover and regularly interact with its virtual assistant.
Windows Central reports that Microsoft is producing a more conversational UI for Cortana that’ll resemble Google Assistant on Android. Although users can already type a question to Cortana, the new interface might more closely resemble a texting conversation, like Allo. These written responses could be accompanied by a voice reply. Voice input will still exist, as well.
A lack of connections can create inefficiencies and tensions between potential collaborators. Looking at these networks raised a question for us: How can we facilitate connections between real-world businesses that would allow them to share resources?
We got so excited about the idea we jumped right into building something: a prototype called Myko, a smart scale and sensors that create a mesh network allowing two businesses to share streaming data that benefits both parties. We took the opportunity to build with Nomad, an open source streaming protocol Reid Williams and Gavin McDermott have been developing at the CoLab.
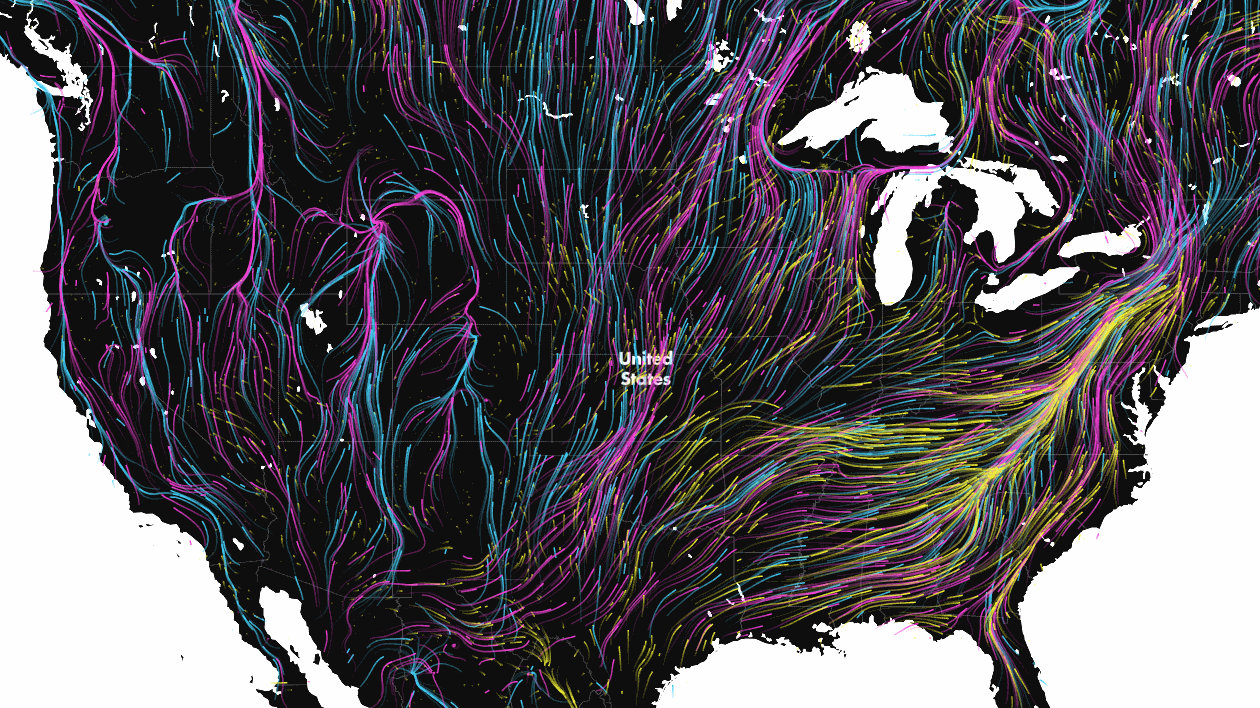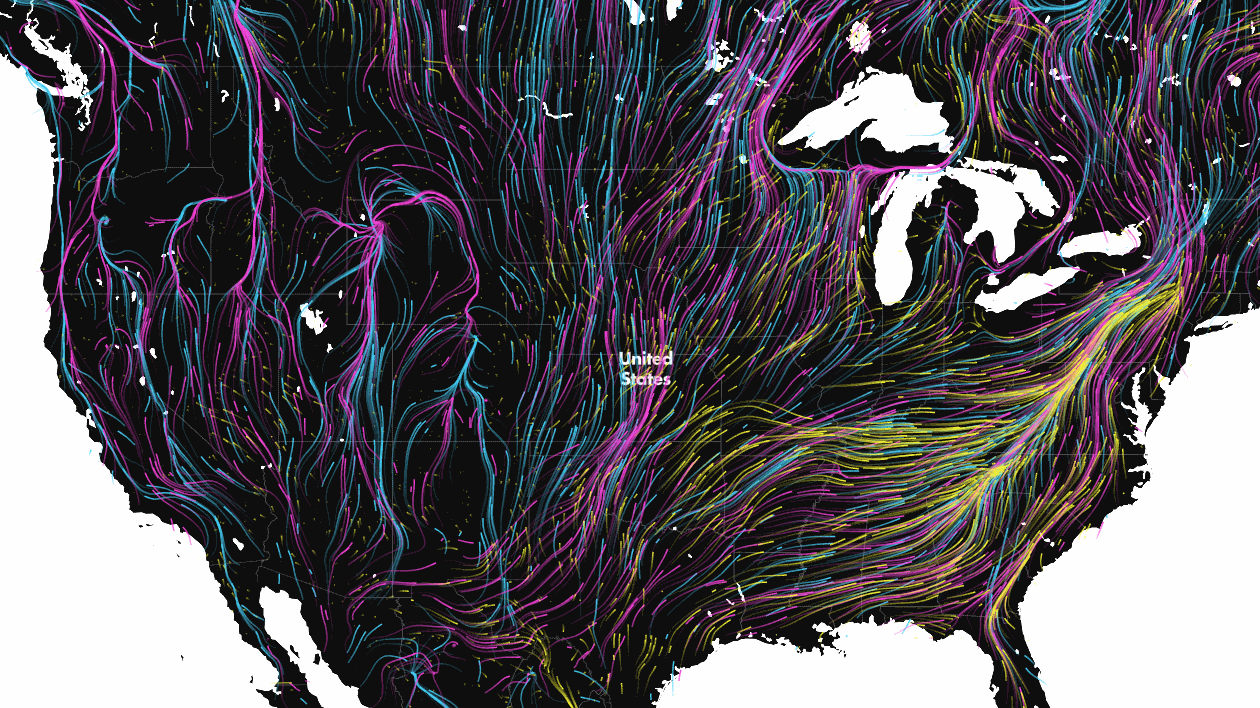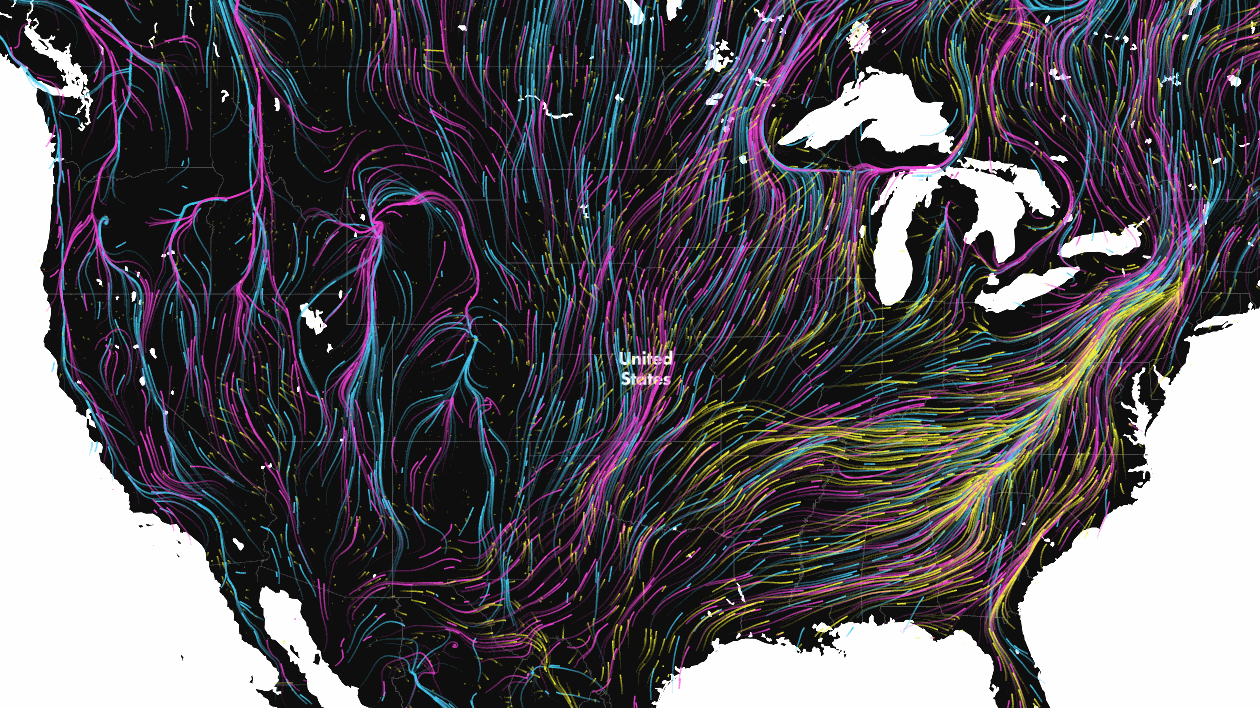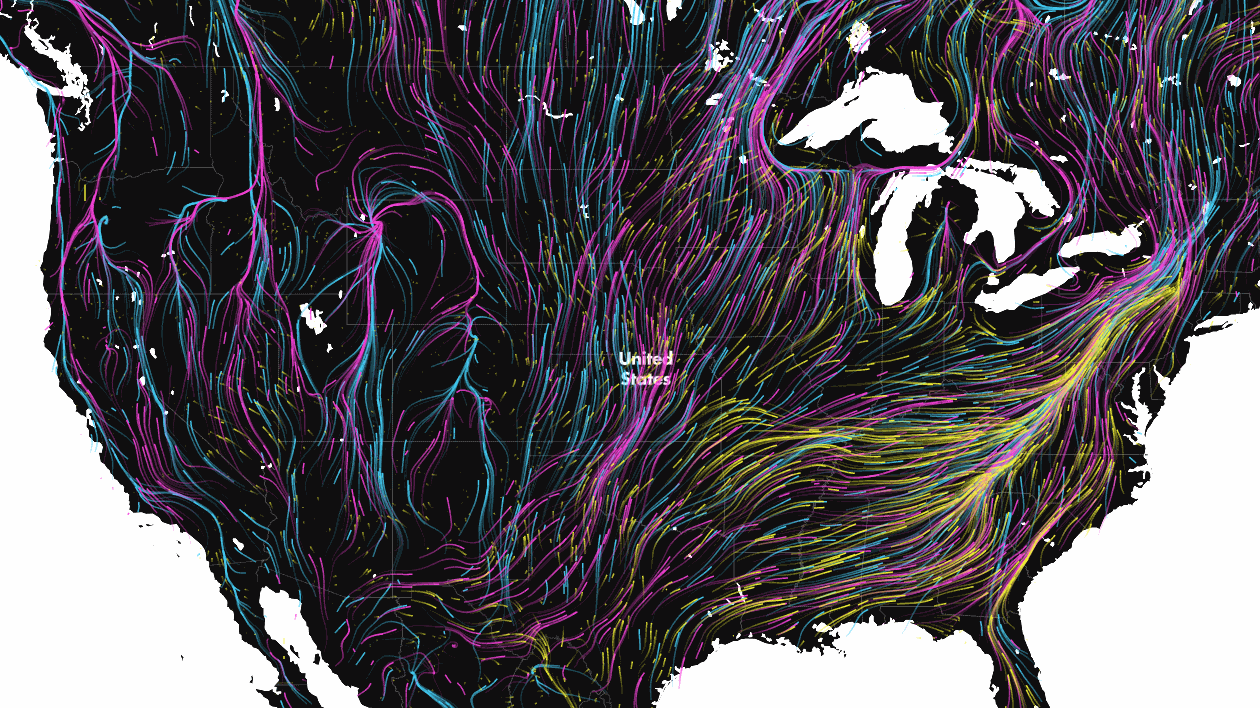
As climate change transforms once favourable environments into inhospitable terrain, animals are forced to seek out new places to live. To highlight just how serious an issue this is, scientists at the Nature Conservancy have created a data visualization that is as mesmerizing as it is worrying.
A governing ethos of the internet has been that whatever flows through it — information, ideas — is up for grabs. In his 2009 manifesto, “Free,” on the new digital economy, Chris Anderson wrote that “it is a unique quality of the digital age that once something becomes software, it inevitably becomes free — in cost, certainly, and often in price.” Anderson and his cohort envisioned a new type of cultural economy that didn’t degrade the effort or labor of production. “Last century’s free was a powerful marketing method,” Anderson noted; “this century’s free is an entirely new economic model.” But that model assumes that everyone within its ecosystem has equal access to resources and capital.
Over the last two decades, the web has pushed every creative medium — print, film, music, even art — into brand-new territory. Creators can now take nontraditional paths to traditional success, and mainstream industries have stretched to accommodate these new digital economic models. A musician like Chance the Rapper no longer needs a record label to win a Grammy, and a comedian like Quinta Brunson can use Instagram and YouTube to land a job producing and starring in videos for BuzzFeed Motion Pictures. And the internet has also allowed for the creation of new types of cultural products, even as we struggle to recognize them as such.
International Society for Computational Biology, DC Chapter
from
College Park, MD On July 12, 2017, we will be hosting a free one-day workshop series with hands-on / open-laptop tutorials focused on various topics in bioinformatics, computational biology and genomics. [free, registration required]
Halifax, Canada The objective of the bigdas@KDD2017 is to provide a professional forum for data scientists, researchers, and engineers across the world to present their latest research findings, innovations, and developments in turning big data health care analytics into fast, easy-to-use, scalable, and highly available services over the Internet. Workshop date is August 14.
NYU Center for Urban Science and Progress; New York, NY
from
New York, NY Tuesday June 20, at 4:00pm. CUSP research seminar + networking reception with Michael Gill, a Moore-Sloan Data Science Fellow at the NYU Center for Data Science and a Research Fellow at the NYU GovLab. [free, registration required]
The purpose of this survey is to identify how prevalent preprint publishing is amongst our membership, to understand our members’ thoughts about how preprint publishing is affecting the ACL reviewing process, and to seek opinions in order to inform future policy in this area.
As robots take over our world, they must not only learn how to communicate with us but also with each other. Recent scholarship has so far demonstrated that it’s possible for two robots to communicate in a shared language in the form of binary vectors. These conversations between the sender (Robot A) and receiver (Robot B) are typically mono-directional, and limited to a fixed number of yes/no answers.
But CDS Master’s student Katrina Evtimova, professor Kyunghyun Cho, Andrew Drozdov (NYU Computer Science), and Douwe Keila (Facebook) all believe that our robots can do better. In “Emergent Language in a Multi-Modal, Multi-Step Referential Game,” they have invented a new conversational game for robots that mimics human communication more closely.
Shogun’s mission is to make powerful machine learning tools available to everyone —researchers, engineers, students — anyone curious to experiment with machine learning to leverage data. The Shogun Machine Learning Toolbox provides efficient implementations of standard and state-of-the-art machine learning algorithms in an accessible, open-source environment.
A core strength of Shogun is that its internals, written in modern C++, can be interfaced from many languages, including Python, Octave, R and more, under a unified interface.
This post discusses how to implement Apple’s new Core ML platform within DSX, which was announced a few days ago at WWDC 2017. Core ML is a platform that allows integration of powerful pre-trained models into iOS and macOS applications.
What We Think About When We Think About Code is a podcast about how humans manage the complexity of software engineering. We interview software engineers to figure out what forms code takes in their mind, and what mental tricks they use, consciously or unconsciously, to navigate and manage code.